

Like most of us, [Peter] had a bit of extra time on his hands during quarantine and decided to take a look back at speech recognition technology in the 1970s. Quickly, he started thinking to himself, “Hmm…I wonder if I could do this with an Arduino Nano?” We’ve all probably had similar thoughts, but [Peter] really put his theory to the test.
The hardware itself is pretty straightforward. There is an Arduino Nano to run the speech recognition algorithm and a MAX9814 microphone amplifier to capture the voice commands. However, the beauty of [Peter’s] approach, lies in his software implementation. [Peter] has a bit of an interplay between a custom PC program he wrote and the Arduino Nano. The learning aspect of his algorithm is done on a PC, but the implementation is done in real-time on the Arduino Nano, a typical approach for really any machine learning algorithm deployed on a microcontroller. To capture sample audio commands, or utterances, [Peter] first had to optimize the Nano’s ADC so he could get sufficient sample rates for speech processing. Doing a bit of low-level programming, he achieved a sample rate of 9ksps, which is plenty fast for audio processing.
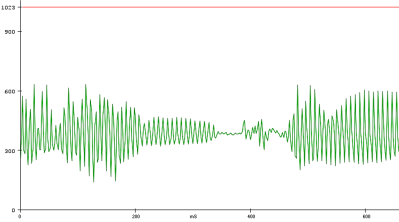
To analyze the utterances, he first divided each sample utterance into 50 ms segments. Think of dividing a single spoken word into its different syllables. Like analyzing the “se-” in “seven” separate from the “-ven.” 50 ms might be too long or too short to capture each syllable cleanly, but hopefully, that gives you a good mental picture of what [Peter’s] program is doing. He then calculated the energy of 5 different frequency bands, for every segment of every utterance. Normally that’s done using a Fourier transform, but the Nano doesn’t have enough processing power to compute the Fourier transform in real-time, so Peter tried a different approach. Instead, he implemented 5 sets of digital bandpass filters, allowing him to more easily compute the energy of the signal in each frequency band.
The energy of each frequency band for every segment is then sent to a PC where a custom-written program creates “templates” based on the sample utterances he generates. The crux of his algorithm is comparing how closely the energy of each frequency band for each utterance (and for each segment) is to the template. The PC program produces a .h file that can be compiled directly on the Nano. He uses the example of being able to recognize the numbers 0-9, but you could change those commands to “start” or “stop,” for example, if you would like to.
[Peter] admits that you can’t implement the type of speech recognition on an Arduino Nano that we’ve come to expect from those covert listening devices, but he mentions small, hands-free devices like a head-mounted multimeter could benefit from a single word or single phrase voice command. And maybe it could put your mind at ease knowing everything you say isn’t immediately getting beamed into the cloud and given to our AI overlords. Or maybe we’re all starting to get used to this. Whatever your position is on the current state of AI, hopefully, you’ve gained some inspiration for your next project.
Recent Comments